
| |
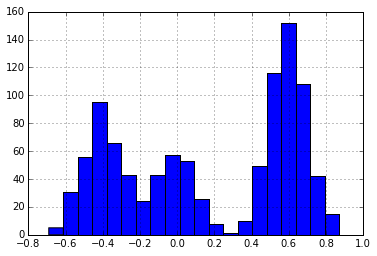
Suppose we receive some data that looks like the following:
| |
| |
1000
It appears that these data exist in three separate clusters. We want to develop a method for finding these latent clusters. One way to start developing a method is to attempt to describe the process that may have generated these data.
For simplicity and sanity, let’s assume that each data point is generated independently of the other. Moreover, we will assume that within each cluster, the data points are identically distributed. In this case, we will assume each cluster is normally distributed and that each cluster has the same variance, $\sigma^2$.
Given these assumptions, our data could have been generated by the following process. For each data point, randomly select 1 of 3 clusters from the distribution $\text{Discrete}(\pi_1, \pi_2, \pi_3)$. Each cluster $k$ corresponds to a parameter $\theta_k$ for that cluster, sample a data point from $\mathcal{N}(\theta_k, \sigma^2)$.
Equivalently, we could consider these data to be generated from a probability distribution with this probability density function:
$$ p(x_i \,|\, \pi, \theta_1, \theta_2, \theta_3, \sigma)= \sum_{k=1}^3 \pi_k\cdot \frac{1}{\sigma\sqrt{2\pi}} \text{exp}\left\{ \frac{-(x_i-\theta_k)^2}{2\sigma^2} \right\} $$where $\pi$ is a 3-dimensional vector giving the mixing proportions. In other words, $\pi_k$ describes the proportion of points that occur in cluster $k$.
That is, the probability distribution describing $x$ is a linear combination of normal distributions.
We want to use this generative model to formulate an algorithm for determining the particular parameters that generated the dataset above. The $\pi$ vector is unknown to us, as is each cluster mean $\theta_k$.
We would also like to know $z_i\in\{1, 2, 3\}$, the latent cluster for each point. It turns out that introducing $z_i$ into our model will help us solve for the other values.
The joint distribution of our observed data (data) along with the assignment variables is given by:
Keeping Everything Straight
Before moving on, we need to devise a way to keep all our data and parameters straight. Following ideas suggested by Keith Bonawitz, let’s define a “state” object to store all of this data.
It won’t yet be clear why we are defining some components of state, however we will use each part eventually! As an attempt at clarity, I am using a trailing underscore in the names of members that are fixed. We will update the other parameters as we try to fit the model.
| |
| |
num_clusters_
suffstats
data_
cluster_means
cluster_variance_
cluster_ids_
assignment
pi
alpha_
hyperparameters_
Gibbs Sampling
The theory of Gibbs sampling tells us that given some data $\bf y$ and a probability distribution $p$ parameterized by $\gamma_1, \ldots, \gamma_d$, we can successively draw samples from the distribution by sampling from
$$\gamma_j^{(t)}\sim p(\gamma_j \,|\, \gamma_{\neg j}^{(t-1)})$$where $\gamma_{\neg j}^{(t-1)}$ is all current values of $\gamma_i$ except for $\gamma_j$. If we sample long enough, these $\gamma_j$ values will be random samples from $p$.
In deriving a Gibbs sampler, it is often helpful to observe that
$$ p(\gamma_j \,|\, \gamma_{\neg j}) = \frac{ p(\gamma_1,\ldots,\gamma_d) }{ p(\gamma_{\neg j}) } \propto p(\gamma_1,\ldots,\gamma_d). $$The conditional distribution is proportional to the joint distribution. We will get a lot of mileage from this simple observation by dropping constant terms from the joint distribution (relative to the parameters we are conditioned on).
The $\gamma$ values in our model are each of the $\theta_k$ values, the $z_i$ values, and the $\pi_k$ values. Thus, we need to derive the conditional distributions for each of these.
Many derivation of Gibbs samplers that I have seen rely on a lot of handwaving and casual appeals to conjugacy. I have tried to add more mathematical details here. I would gladly accept feedback on how to more clearly present the derivations! I have also tried to make the derivations more concrete by immediately providing code to do the computations in this specific case.
Conditional Distribution of Assignment
For berevity, we will use
$$ p(z_i=k \,|\, \cdot)= p(z_i=k \,|\, z_{\neg i}, \pi, \theta_1, \theta_2, \theta_3, \sigma, \bf x ). $$Because cluster assignements are conditionally independent given the cluster weights and paramters,
\begin{align} p(z_i=k \,|\, \cdot) &\propto \prod_i^n \prod_k^K \left( \pi_k \frac{1}{\sigma\sqrt{2\pi}} \text{exp}\left\{ \frac{-(x_i-\theta_k)^2}{2\sigma^2} \right\} \right)^{\delta(z_i, k)} \\ &\propto \pi_k \cdot \frac{1}{\sigma\sqrt{2\pi}} \text{exp}\left\{ \frac{-(x_i-\theta_k)^2}{2\sigma^2} \right\} \end{align}This equation intuitively makes sense: point $i$ is more likely to be in cluster $k$ if $k$ is itself probable ($\pi_k\gg 0$) and $x_i$ is close to the mean of the cluster $\theta_k$.
For each data point $i$, we can compute $p(z_i=k \,|\, \cdot)$ for each of cluster $k$. These values are the unnormalized parameters to a discrete distribution from which we can sample assignments.
Below, we define functions for doing this sampling. sample_assignment will generate a sample from the posterior assignment distribution for the specified data point. update_assignment will sample from the posterior assignment for each data point and update the state object.
| |
Conditional Distribution of Mixture Weights
We can similarly derive the conditional distributions of mixture weights by an application of Bayes theorem. Instead of updating each component of $\pi$ separately, we update them together (this is called blocked Gibbs).
\begin{align} p(\pi \,|\, \cdot)&= p(\pi \,|\, \bf{z}, \theta_1, \theta_2, \theta_3, \sigma, \mathbf{x}, \alpha )\\ &\propto p(\pi \,|\, \mathbf{x}, \theta_1, \theta_2, \theta_3, \sigma, \alpha ) p(\bf{z}\ \,|\, \mathbf{x}, \theta_1, \theta_2, \theta_3, \sigma, \pi, \alpha )\\ &= p(\pi \,|\, \alpha ) p(\bf{z}\ \,|\, \mathbf{x}, \theta_1, \theta_2, \theta_3, \sigma, \pi, \alpha )\\ &= \prod_{i=1}^K \pi_k^{\alpha/K - 1} \prod_{i=1}^K \pi_k^{\sum_{i=1}^N \delta(z_i, k)} \\ &=\prod_{k=1}^3 \pi_k^{\alpha/K+\sum_{i=1}^N \delta(z_i, k)-1}\\ &\propto \text{Dir}\left( \sum_{i=1}^N \delta(z_i, 1)+\alpha/K, \sum_{i=1}^N \delta(z_i, 2)+\alpha/K, \sum_{i=1}^N \delta(z_i, 3)+\alpha/K \right) \end{align}Here are Python functions to sample from the mixture weights given the current state and to update the mixture weights in the state object.
| |
Conditional Distribution of Cluster Means
Finally, we need to compute the conditional distribution for the cluster means.
We assume the unknown cluster means are distributed according to a normal distribution with hyperparameter mean $\lambda_1$ and variance $\lambda_2^2$. The final step in this derivation comes from the normal-normal conjugacy. For more information see section 2.3 of this and section 6.2 this.)
\begin{align} p(\theta_k \,|\, \cdot)&= p(\theta_k \,|\, \bf{z}, \pi, \theta_{\neg k}, \sigma, \bf x, \lambda_1, \lambda_2 ) \\ &\propto p(\left\{x_i \,|\, z_i=k\right\} \,|\, \bf{z}, \pi, \theta_1, \theta_2, \theta_3, \sigma, \lambda_1, \lambda_2) \cdot\\ &\phantom{==}p(\theta_k \,|\, \bf{z}, \pi, \theta_{\neg k}, \sigma, \lambda_1, \lambda_2)\\ &\propto p(\left\{x_i \,|\, z_i=k\right\} \,|\, \mathbf{z}, \theta_k, \sigma) p(\theta_k \,|\, \lambda_1, \lambda_2)\\ &= \mathcal{N}(\theta_k \,|\, \mu_n, \sigma_n)\\ \end{align}$$ \sigma_n^2 = \frac{1}{ \frac{1}{\lambda_2^2} + \frac{N_k}{\sigma^2} } $$and
$$\mu_n = \sigma_n^2 \left( \frac{\lambda_1}{\lambda_2^2} + \frac{n\bar{x_k}}{\sigma^2} \right) $$Here is the code for sampling those means and for updating our state accordingly.
| |
Doing each of these three updates in sequence makes a complete Gibbs step for our mixture model. Here is a function to do that:
| |
Initially, we assigned each data point to a random cluster. We can see this by plotting a histogram of each cluster.
| |
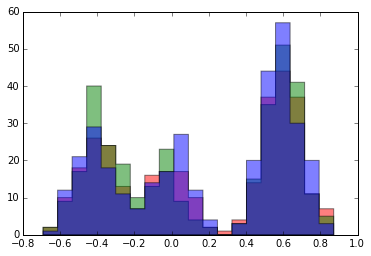
Each time we run gibbs_step, our state is updated with newly sampled assignments. Look what happens to our histogram after 5 steps:
| |
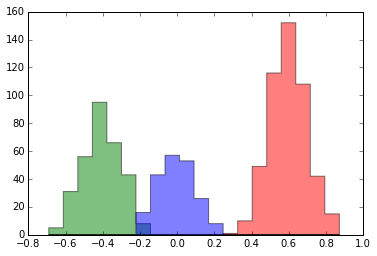
Suddenly, we are seeing clusters that appear very similar to what we would intuitively expect: three Gaussian clusters.
Another way to see the progress made by the Gibbs sampler is to plot the change in the model’s log-likelihood after each step. The log likehlihood is given by:
$$ \log p(\mathbf{x} \,|\, \pi, \theta_1, \theta_2, \theta_3) \propto \sum_x \log \left( \sum_{k=1}^3 \pi_k \exp \left\{ -(x-\theta_k)^2 / (2\sigma^2) \right\} \right) $$We can define this as a function of our state object:
| |
| |
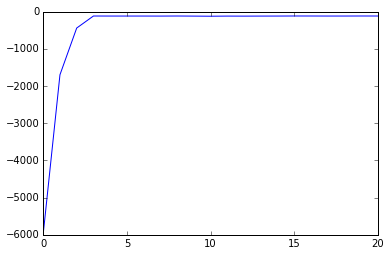
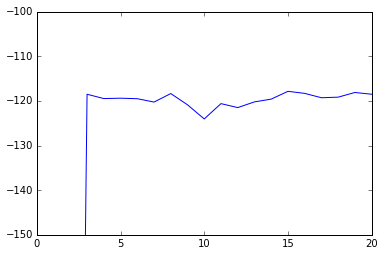
See that the log likelihood improves with iterations of the Gibbs sampler. This is what we should expect: the Gibbs sampler finds state configurations that make the data we have seem “likely”. However, the likelihood isn’t strictly monotonic: it jitters up and down. Though it behaves similarly, the Gibbs sampler isn’t optimizing the likelihood function. In its steady state, it is sampling from the posterior distribution. The state after each step of the Gibbs sampler is a sample from the posterior.
| |
In another post, I show how we can “collapse” the Gibbs sampler and sampling the assignment parameter without sampling the $\pi$ and $\theta$ values. This collapsed sampler can also be extended to the model with a Dirichet process prior that allows the number of clusters to be a parameter fit by the model.
Notation Helper
$N_k$,
state['suffstat'][k].N: Number of points in cluster $k$.$\theta_k$,
state['suffstat'][k].theta: Mean of cluster $k$.$\lambda_1$,
state['hyperparameters_']['mean']: Mean of prior distribution over cluster means.$\lambda_2^2$,
state['hyperparameters_']['variance']Variance of prior distribution over cluster means.$\sigma^2$,
state[cluster_variance_]: Known, fixed variance of clusters.
The superscript $(t)$ on $\theta_k$, $pi_k$, and $z_i$ indicates the value of that variable at step $t$ of the Gibbs sampler.